Introduction
Artificial intelligence (AI) and machine learning (ML) have revolutionized various industries by enabling automation, data-driven decision-making, and intelligent problem-solving. As machine learning models grow in complexity, researchers and engineers seek more efficient ways to improve their performance while maintaining scalability. One such approach is the Mixture of Experts (MoE), an ensemble learning technique that enhances model performance by dynamically selecting specialized models for different types of inputs.
The concept of Mixture of Experts was first introduced in the early 1990s by Ronald Jacobs, Michael Jordan, and Geoffrey Hinton as a method to improve neural network efficiency by dividing complex problems into simpler subproblems. Over the years, the approach has evolved with advancements in deep learning and has been integrated into modern AI systems, including Google’s Switch Transformer, which utilizes MoE for efficient language modeling. Today, MoE is widely used in large-scale AI applications to optimize computation and enhance scalability.
In this article, we will explore:
- What Mixture of Experts (MoE)
- How it works
- Its advantages and challenges
- Applications across various industries
- Comparisons with traditional AI models
- Future trends in MoE
What Is Mixture of Experts (MoE)?
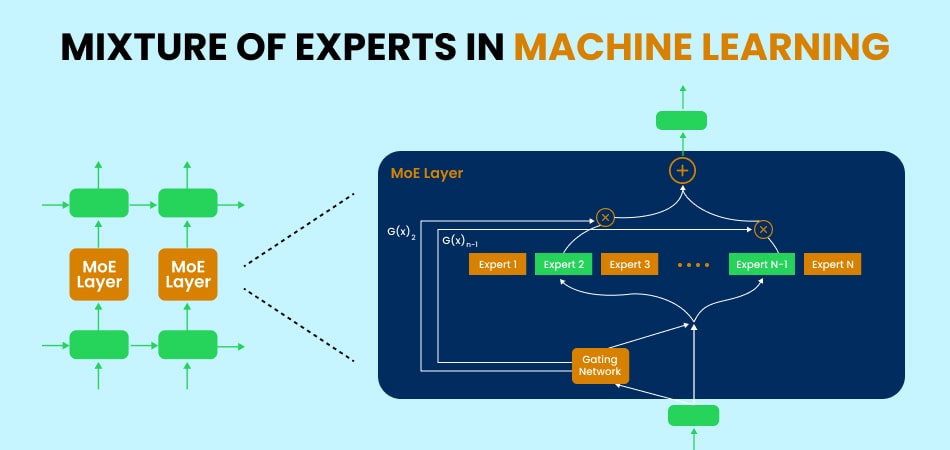
Mixture of Experts (MoE) is an ensemble learning method designed to improve model efficiency by distributing tasks across multiple specialized models, known as experts. Instead of relying on a monolithic model to handle all input types, MoE employs a gating network to determine which experts are best suited for processing specific inputs.
Key Components of MoE
- Experts:
- Individual models trained to specialize in different aspects of a problem.
- Each expert handles a subset of the input space, leading to better performance.
- Gating Network:
- A neural network that determines which experts should process an input.
- It assigns weights to each expert based on relevance to the given input.
- Final Decision Mechanism:
- Aggregates outputs from selected experts to generate the final result.
- Uses a weighted sum or other fusion techniques for final predictions.
This model enables efficient learning, as only the most relevant experts are activated per input, reducing unnecessary computations.
How Does Mixture of Experts Work?

The MoE model works through a step-by-step process where input data is routed dynamically to specialized models. Below is a breakdown of its working mechanism:
Step 1: Data Input and Preprocessing
- The model receives raw input data (e.g., text, image, numerical data).
- Preprocessing techniques such as normalization, feature extraction, or data augmentation are applied.
Step 2: Expert Selection by the Gating Network
- The gating network analyzes the input and determines which experts should process it.
- It assigns different weights to each expert, emphasizing those most relevant to the input type.
Step 3: Expert Computation
- The selected experts process the input data independently.
- Each expert produces a separate prediction or decision based on its trained knowledge.
Step 4: Aggregation of Outputs
- The weighted outputs of the selected experts are combined to form the final prediction.
- Methods like softmax-based averaging or attention mechanisms are commonly used.
Step 5: Model Optimization and Learning
- The MoE model undergoes backpropagation and training to adjust both the expert models and the gating network.
- Over time, the gating network learns to select the most suitable experts for different input types.
This dynamic allocation of computational resources ensures high efficiency, as only relevant experts are activated, minimizing redundancy in processing.
Advantages of Mixture of Experts
1. Improved Computational Efficiency
- Instead of processing all inputs with a single large model, MoE activates only necessary experts, reducing computational overhead.
2. Enhanced Scalability
- MoE models can scale effectively as additional experts can be added without significantly increasing the overall complexity.
3. Better Interpretability
- Since each expert specializes in a specific subproblem, it becomes easier to understand how decisions are made within the model.
4. Parallel Processing Capability
- Experts operate independently, making MoE highly suitable for parallel computing environments.
5. Adaptability to Diverse Tasks
- MoE models can dynamically adjust to different types of inputs, making them versatile for multi-domain applications.
Challenges and Limitations of Mixture of Experts
Despite its advantages, Mixture of Experts comes with some challenges:
| Challenge | Description |
| Increased Complexity | Managing multiple expert models requires additional computational resources. |
| Training Difficulties | Coordinating expert training can be challenging and requires careful tuning. |
| Overfitting Risk | If not regulated properly, experts may overfit to specific subsets of data. |
| Load Balancing Issues | Some experts may get underutilized if the gating network is biased. |
| Resource Consumption | Deploying multiple experts can be computationally expensive. |
Comparison: Mixture of Experts vs. Traditional Models
| Feature | Mixture of Experts (MoE) | Traditional Deep Learning Models |
| Architecture | Multiple specialized experts & gating network | Single unified model |
| Computational Efficiency | Activates only relevant experts | Uses full model capacity for all inputs |
| Interpretability | Easier to analyze decision paths | Difficult to interpret decisions |
| Training Complexity | High (requires multiple models) | Moderate to high |
| Scalability | Highly scalable due to distributed nature | Limited scalability |
| Resource Utilization | Selective computation (efficient) | Full model computation (expensive) |
Applications of Mixture of Experts

1. Natural Language Processing (NLP)
- Used in Google’s Switch Transformer to improve language model efficiency.
- Helps in machine translation, text summarization, and chatbots.
2. Computer Vision
- Applied in image recognition and object detection tasks.
- Enhances model accuracy by leveraging specialized feature detectors.
3. Healthcare and Medical Diagnosis
- Assists in disease prediction and personalized treatment plans.
- Uses multiple experts to analyze different health parameters.
4. Finance and Fraud Detection
- Helps in detecting fraudulent transactions.
- Assigns different experts to analyze different fraud patterns.
5. Autonomous Systems
- Applied in self-driving cars to analyze road conditions and make real-time decisions.
Future of Mixture of Experts in AI
The future of MoE in AI is promising, with several advancements expected:
- Improved Gating Networks: Developing more efficient selection mechanisms.
- Hybrid MoE Models: Combining MoE with reinforcement learning for better adaptability.
- Decentralized MoE Systems: Enabling distributed AI models across multiple devices.
- Automated Expert Generation: Using AI-driven techniques to generate and optimize experts dynamically.
Conclusion
Mixture of Experts (MoE) represents a powerful paradigm shift in machine learning, enabling efficient decision-making by leveraging multiple specialized models. While MoE presents certain challenges such as training complexity and resource consumption, its advantages in scalability, interpretability, and computational efficiency make it a promising approach for future AI developments.
As technology evolves, MoE is likely to be widely adopted across various fields, from NLP and computer vision to finance and healthcare. By understanding its fundamental mechanisms and applications, businesses and researchers can unlock its full potential to drive innovation in AI-powered solutions.


